เครื่องแปลภาษาคือ เครื่องมือที่ใช้สำหรับการแปลข้อความจำนวนมากๆ จากภาษาหนึ่งไปยังอีกภาษาหนึ่ง โดยที่สามารถป้อนข้อมูลภาษาต้นทางเป็นข้อความหรือเสียงก็ได้ และจะได้ภาษาปลายทางเป็นข้อความหรือเสียงก็ได้เช่นกันซึ่งจะช่วยให้วงการการแปลสามารถแปลข้อความได้เป็นจำนวนมากและรวดเร็ว ในยุคที่ต้องการข้อมูลข่าวสารอย่างรวดเร็ว
ประวัติการทำวิจัยและพัฒนาเครื่องแปลภาษา
การทำวิจัยและพัฒนาเครื่องแปลภาษาเป็นงานแขนงหนึ่งในศาสตร์แห่งการประมวลผลภาษาธรรมชาติ (Natural Language Processing)เครื่องแปลภาษาเครื่องแรกได้กำเนิดขึ้นประมาณปี ค.ศ. ๑๙๓๐ เครื่องแปลภาษาเป็นซอฟต์แวร์ที่
เครื่องแปลภาษาในยุคปี ค.ศ. ๑๙๘๐
งานวิจัยและพัฒนาเครื่องแปลภาษาในยุคนั้นยังให้ความสำคัญกับวากยสัมพันธ์ของภาษาและใช้วิธีการ "เปลี่ยน" (transfer approach)ตัวอย่างเช่น ระบบเอเรียน (Ariane) ของมหาวิทยาลัยเกรอนอบล์ ประเทศฝรั่งเศส ระบบเมทัล ของเทกซัส ระบบซูซี ของ Sarbrukenระบบ MU ของมหาวิทยาลัยเกียวโต รวมถึงโครงการ Multilingual Eurotra ของกลุ่มประชาคมยุโรป
ต่อมามีการนำวิธีการใช้ภาษากลาง (inter-lingual approach) เข้ามาใช้ เพื่อที่จะทำการแปลแบบหลายภาษา (multilingual machine translation)ให้ได้ผล เช่น โครงการ DLT และ โรเซตตา(Rosetta) ประเทศเนเธอร์แลนด์ รวมทั้งโครงการระบบเครื่องแปลหลากภาษาสำหรับภาษาอาเซียน๕ ภาษา คือ ภาษาญี่ปุ่น ภาษาจีน ภาษามาเลเซียภาษาอินโดนีเซีย และภาษาไทย
การพัฒนาเครื่องแปลภาษาในยุคนี้มีแนวคิดเปลี่ยนไปจากเดิมคือ เริ่มมองว่าเครื่องแปลภาษาเป็นเครื่องมือที่จะช่วยแปลภาษาเท่านั้น แต่ไม่สามารถนำมาทดแทนนักแปลภาษามืออาชีพได้แนวคิดเช่นนี้ก่อให้เกิดการรวมตัวของนักวิจัยเพื่อหาแนวทางใหม่ๆในการทำวิจัยและพัฒนา ซึ่งสามารถสรุปแนวทางที่เกิดขึ้นในยุคนี้ได้ดังนี้
๑. เครื่องแปลภาษาแบบใช้กฎไวยากรณ์ สมมติฐานของการพัฒนาเครื่องแปลภาษาแบบใช้กฎไวยากรณ์ก็คือ การมีกระบวนการวิเคราะห์และการสร้างรูปแทน (representation)ความหมายของภาษาต้นทาง และสร้างภาษาปลายทางจากรูปแทนนั้น โดยที่รูปแทนจะต้องไม่มีความกำกวมทั้งในระดับคำและโครงสร้าง โดยมีการวิเคราะห์ภาษาต้นทางด้วยความรู้ทางภาษาศาสตร์ ซึ่งประมวลผลออกมาเป็นกฎไวยากรณ์และมีวิธีใช้เพื่อให้สามารถไปถึงจุดหมายนั้นได้หลายวิธี ดังนี้
๑.๑ เครื่องแปลภาษาแบบ "เปลี่ยน"แนวทางการใช้วิธีการ "เปลี่ยน" นั้น ได้แก่ระบบเอเรียน และระบบยูโรทรา ฯลฯ ซึ่งเป็นระบบที่ให้ความสำคัญกับวากยสัมพันธ์ของภาษา และมีการทำงานเป็นขั้นตอน ดังนี้
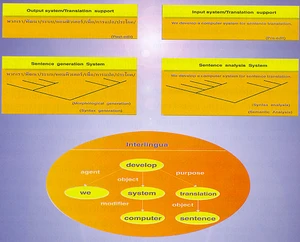
๑.๒ เครื่องแปลภาษาแบบ "ภาษากลาง"(Interlingual Approach)การทำวิจัยเครื่องแปลภาษาด้วยการใช้ภาษากลางนั้นเริ่มต้นที่มหาวิทยาลัย Carnegie - Melon ซึ่งทำวิจัยและพัฒนา Knowledge - based MTsystem โดยมีแนวคิดว่า นอกเหนือจากการใช้ความรู้ทางภาษาศาสตร์แล้ว ในการแปลภาษาจะต้องมีความเข้าใจเรื่องหลักภาษาด้วย จึงมีการแปลงรูปแทนทางวากยสัมพันธ์เป็นรูปแทนทางอรรถศาสตร์ โดยใช้ความรู้จากฐานความรู้ในโดเมนใดๆ ซึ่งแสดงเป็นโครงข่าย (network) ที่แสดง actual events
๒. เครื่องแปลภาษาแบบใช้คลังข้อความ(Corpus - based Approach) แนวคิดการทำวิจัยและพัฒนาเครื่องแปลภาษาได้เริ่มเข้าสู่ยุคใหม่ ซึ่งมีการเก็บรวบรวมข้อความจำนวนมากที่เรียกว่า คลังข้อความ(Corpus base) เพื่อนำไปศึกษาวิจัย โดยอ้างอิงข้อมูลขนาดใหญ่ที่ใช้จริงในภาษา และมีการดึงข้อมูลจากคลังข้อความไปใช้ในการวิเคราะห์ภาษาหรือการสร้างภาษาโดยตรง จึงก่อให้เกิดวิธีการนำไปใช้ดังต่อไปนี้
๒.๑ วิธีอาศัยค่าสถิติ (Statistic Approach)ในช่วงปลายคริสต์ทศวรรษ ๑๙๘๐ โครงการIBM candide Research (Brown et all. 1980,1990) ได้อาศัยวิธีการทางสถิติในการวิเคราะห์ และการสร้างภาษา โดยอาศัยคลังข้อความขนาดใหญ่ที่มีชื่องว่า Canadian Hansard ซึ่งได้เก็บบันทึกการอภิปรายในสภาไว้เป็น ๒ ภาษาคือภาษาอังกฤษ และภาษาฝรั่งเศส วิธีการที่นำมาใช้คือ การหาขอบเขตของประโยค ๒ ภาษาที่ตรงกันจากคลังข้อความที่เป็นคู่ภาษา จากนั้นนำมาคำนวณหาค่าความเป็นไปได้ของคำในภาษาต้นทางว่าตรงกับภาษาปลายทางกี่คำ โดยคำนวณค่าความเป็นไปได้จากการจับคู่คู่คำที่อยู่ติดกัน (bigram)ของภาษาอังกฤษ กับคู่คำที่อยู่ติดกัน (bigram)ของภาษาฝรั่งเศส ซึ่งผลสำเร็จที่สามารถแปลได้มีความถูกต้องประมาณ ๔๘ %
ต่อมามีการปรับปรุงการทำวิจัยและพัฒนาในเรื่องนี้ โดยปรับการคำนวณค่าความเป็นไปได้ให้ถูกต้องมากยิ่งขึ้น นอกจากนั้น นักวิจัยบางคนก็นำความรู้ทางภาษาศาสตร์เรื่องคำและไวยากรณ์มาใช้ร่วมกัน เพื่อให้งานนั้นถูกต้องยิ่งขึ้น
๒.๒ วิธีการแปลแบบใช้ประโยคตัวอย่าง(Example base Approach)ในกลางคริสต์ทศวรรษ ๑๙๘๐ นากาโอะ(Nagao) ได้เสนอวิธีการแปลโดยการใช้ประโยคตัวอย่างจากคลังข้อความคู่ภาษาขนาดใหญ่ ซึ่งโปรแกรมจะคำนวณว่า ประโยคที่มีปรากฏว่าแปลไว้ในคลังตัวอย่าง และดึงขึ้นมาใช้ โครงการATR ซึ่งมีเครื่องแปลภาษาแบบใช้วิธี "เปลี่ยน"ก็ได้นำวิธีนี้มาใช้ โดยเลือกเก็บประโยคตัวอย่างซึ่งได้มาจากการคำนวณค่าระยะะห่างของคำที่มีความหมายใกล้เคียงกันในอภิธานศัพท์ (Thesaurus) และจะใช้การ "เปลี่ยน" ในระดับต่างๆ เช่นระดับคำ ระดับรูปแบบ และระดับวากยสัมพันธ์เช่น ในภาษาญี่ปุ่น โครงสร้าง N1 no N2 จะเปลี่ยนไปให้ตรงกับ N2 of N1 แต่ก็ไม่เสมอไปเช่น จะใช้สำนวนว่า fee for the conference มากกว่า fee of the conference และจะใช้ conferencein Tokyo มากกว่า conference of Tokyo ดังนั้น จึงมีการเก็บประโยคตัวอย่างเหล่านี้ไว้
